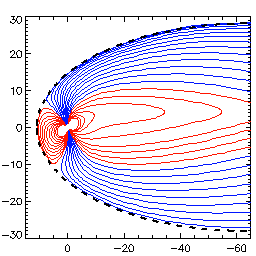
Field Lines of the Earth's Magnetosphere
Magnetic field lines of the
Earth's Magnetosphere
.
This is a model field, obtained from
data of many satellites
.
It shows the field when the magnetic axis of Earth is not quite perpendicular to the solar wind but is "tilted."